隐私是开发合乎道德的人工智能技术的关键原则。但是,由于人工智能的技术进步远远超过了对这些技术的监管,因此减轻包含这些技术的商品和服务的隐私风险的责任主要落在这些商品和服务的开发者身上。

对于人工智能从业者来说,这是一个棘手的命题,它首先要切实定义人工智能驱动的隐私风险,以便在新技术的研发阶段解决这些风险。
虽然有一种隐私分类法具有完善的研究驱动基础(opens in new window),但突破性的人工智能技术进步可能会带来这些新技术所特有的前所未有的隐私风险。
卡内基梅隆大学人机交互研究所(HCII)助理教授Sauvik Das(opens in new window)表示:“从业者在创建人工智能产品和服务时需要更多关于如何保护隐私的指导。
“关于人工智能会带来什么或不会带来什么风险,以及它能做什么或不能做什么,有很多炒作。但是,关于人工智能的现代进步如何以某种有意义的方式改变隐私风险,目前还没有明确的资源。
在他们的论文中,“深度伪造、颅相学、监视等等!AI 隐私风险分类法,“(opens in new window) Das 和一组研究人员试图为这一权威资源奠定基础。
该研究团队还包括卡内基梅隆大学的研究人员 Hao-Ping (Hank) Lee(opens in new window)、Yu-Ju (Marisa) Yang(opens in new window)和 Jodi Forlizzi(opens in new window),他们通过分析 321 起记录在案的 AI 隐私事件,构建了 AI 隐私风险分类法。该团队的目标是编纂这些事件中描述的人工智能技术的独特功能和要求如何产生新的隐私风险,加剧已知风险,或者以其他方式没有有意义地改变已知风险。
Das 和他的团队引用了 Daniel J. Solove 在 2006 年发表的论文“隐私分类法”(在新窗口中打开), 作为传统隐私风险的基线分类法,这些风险早于人工智能的现代进步。然后,他们交叉引用了记录在案的人工智能隐私事件,以了解它们如何以及是否符合Solove的分类法。
“如果我们看到人工智能造成伤害的事件正在挑战这种分类法,那么这就是人工智能以某种方式改变隐私伤害的一个例子,”达斯解释说。“但是,如果该事件完全符合分类法,那么它可能只是加剧了现有的伤害,或者它根本没有有意义地改变隐私伤害。
在通过Solove分类法检查记录在案的AI隐私事件时,该团队确定了AI技术新创造或加剧的12个高级隐私风险,如下表所示。
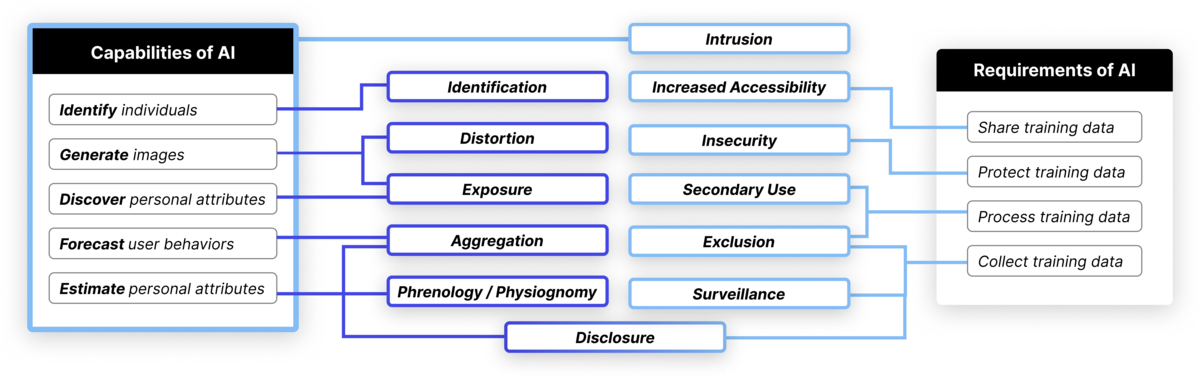
研究人员确定了人工智能的独特功能和/或要求可能带来的12种隐私风险。例如,人工智能的能力创造了识别、扭曲、相貌和不必要的披露等新风险(紫色);由于不安全,人工智能的数据要求可能会加剧监视、排斥、二次使用和数据泄露的风险(浅蓝色)。
“我们设定了一个与产品和服务相关的鸿沟,并以两种方式进入分类法:人工智能的要求和人工智能的能力,”达斯说。
“人工智能的要求是指人工智能的数据和基础设施要求加剧了Solove分类法中已经捕获的隐私风险的方式。
“人工智能的能力是指它能够做一些事情,比如推断用户的信息,以预测他们下一步要去哪里或下一步要做什么。
研究人员发现,人工智能技术导致的新隐私风险的两个例子是相貌(长期以来被揭穿的伪科学艺术,即从面部特征判断一个人的性格)和深度伪造色情内容的扩散。
“在Solove的分类法中有一个’失真’类别,它解决了有关你的信息可能被用来对付你的情况,在一般的类别中,这将捕捉到这种深度伪造的使用,”Das说。“但是,人工智能的能力从根本上说是新的,它可以在一种情况下获取关于你的信息,并生成它,在另一种情况下制作关于你的逼真的内容,这是信息和计算技术过去无法做到的,这种方式并不明显,或者至少不是没有很多努力。它代表了过去从未存在过的一种新的扭曲风险类别,而人工智能从根本上改变了这一点。
Das 和他的团队将于 5 月在檀香山举行的 Association for Computing Machinery (opens in new window)2024 Computer-Human Interaction Conference(opens in new window) 上展示他们的研究结果。他们希望在当前研究的基础上,使从业者和监管机构在开发和管理这些技术时更容易使用他们的分类法来降低隐私风险。
“很快,我们将拥有这种分类法的网络版本,因此这应该使它更容易访问,”Das说。“我们希望这种分类法能为从业者提供一个清晰的路线图,说明人工智能可能带来的隐私风险类型。
新闻旨在传播有益信息,英文版原文来自https://www.cmu.edu/news/stories/archives/2024/march/cylab-researchers-develop-a-taxonomy-for-ai-privacy-risks