
作物地图可帮助科学家和政策制定者跟踪全球粮食供应,并估计它们如何随着气候变化和人口增长而变化。但是,要获得从一个农场到另一个农场种植的作物类型的准确地图,往往需要实地调查,而只有少数国家有资源来维护。
现在,麻省理工学院的工程师已经开发出一种方法,可以快速准确地标记和绘制作物类型,而无需亲自评估每个农场。该团队的方法结合了谷歌街景图像、机器学习和卫星数据,自动确定整个地区种植的作物,从一英亩的一小部分到另一英亩。
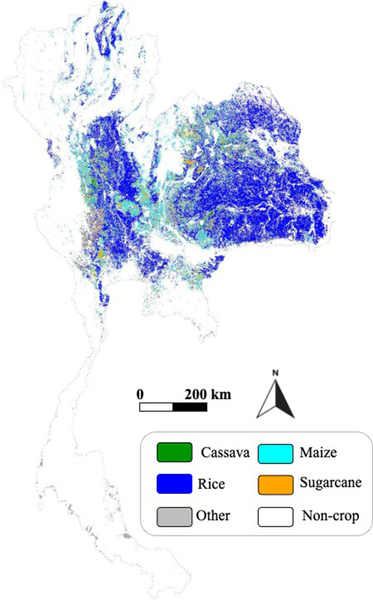
研究人员使用这项技术自动生成了泰国的第一个全国性作物地图,泰国是一个小农国家,小型独立农场构成了主要的农业形式。该团队绘制了泰国四种主要作物(水稻、木薯、甘蔗和玉米)的国界地图,并确定了四种作物中的哪一种,每10米种植一次,而且没有间隙,在全国范围内。由此产生的地图达到了93%的准确率,研究人员表示,这与高收入大农场国家的实地测绘工作相当。
该团队正在将他们的制图技术应用于其他国家,例如印度,那里的小农场维持了大部分人口,但从农场到农场种植的作物类型历来记录不佳。
“这是关于世界各地种植的知识的长期差距,”麻省理工学院机械工程系和数据、系统与社会研究所(IDSS)的d’Arbeloff职业发展助理教授Sherrie Wang说。“最终目标是了解农业成果,如产量,以及如何更可持续地耕作。关键的初步步骤之一是绘制正在种植的东西——您可以绘制的地图越精细,您可以回答的问题就越多。
Wang将与麻省理工学院研究生Jordi Laguarta Soler和农业科技公司PEAT GmbH的Thomas Friedel一起,在本月晚些时候的AAAI人工智能会议上发表一篇论文,详细介绍他们的绘图方法。
地面实况
小农农场通常由一个家庭或农民经营,他们以自己饲养的农作物和牲畜为生。据估计,小农户养活了世界三分之二的农村人口,生产了世界80%的粮食。密切关注种植的内容和地点对于跟踪和预测世界各地的粮食供应至关重要。但这些小农场大多位于中低收入国家,那里很少有资源用于跟踪各个农场的作物类型和产量。
作物测绘工作主要在美国和欧洲等高收入地区进行,政府农业机构负责监督作物调查,并派遣评估员到农场,从一块田地到另一块田地标记作物。然后,这些“地面实况”标签被输入到机器学习模型中,这些模型在实际作物的地面标签和相同田地的卫星信号之间建立连接。然后,他们标记和绘制更广阔的农田,评估人员没有覆盖这些农田,但卫星会自动覆盖。
“低收入和中等收入国家缺乏的是我们可以将卫星信号与地面标签联系起来,”Laguarta Soler说。“首先,在世界大部分地区,获得这些基本事实来训练模型是有限的。
该团队意识到,虽然许多发展中国家没有资源来维持作物调查,但他们有可能使用另一个地面数据来源:由谷歌街景和Mapillary等服务捕获的路边图像,这些服务将汽车发送到整个地区,使用行车记录仪和屋顶摄像头拍摄连续的360度图像。
近年来,这些服务已经能够进入低收入和中等收入国家。虽然这些服务的目标不是专门捕捉农作物的图像,但麻省理工学院的团队发现他们可以搜索路边图像来识别农作物。
裁剪图像
在他们的新研究中,研究人员使用了在泰国各地拍摄的谷歌街景(GSV)图像 – 该服务最近对这个国家进行了相当彻底的成像,主要由小农农场组成。
从在泰国各地随机采样的20多万张GSV图像开始,该团队过滤掉了描绘建筑物,树木和一般植被的图像。大约有81,000张图像与作物有关。他们留出了2000个这样的作物,寄给了一位农艺师,农艺师用肉眼确定并标记了每种作物的类型。然后,他们训练了一个卷积神经网络,使用各种训练方法为其他 79,000 张图像自动生成作物标签,包括 iNaturalist(一个基于网络的众包生物多样性数据库)和 GPT-4V,一种“多模态大型语言模型”,使用户能够输入图像并要求模型识别图像所描绘的内容。对于 81,000 张图像中的每张图像,该模型都生成了图像可能描绘的四种作物之一的标签——水稻、玉米、甘蔗或木薯。
然后,研究人员将每个标记的图像与在整个生长季节从同一位置拍摄的相应卫星数据配对。这些卫星数据包括多个波长的测量值,例如某个位置的绿度和反射率(这可能是水的标志)。
“每种类型的作物在这些不同的波段上都有一定的特征,这些特征在整个生长季节都会发生变化,”Laguarta Soler指出。
该团队训练了第二个模型,以在位置的卫星数据与其相应的作物标签之间建立关联。然后,他们使用这个模型来处理该国其他地区的卫星数据,这些地区没有生成或无法获得作物标签。然后,根据该模型学习到的关联,它在泰国各地分配作物标签,以10平方米的分辨率生成全国范围内的作物类型地图。
这张史无前例的作物地图包括与研究人员最初搁置的 2,000 张 GSV 图像相对应的位置,这些图像由树艺师标记。这些人工标记的图像用于验证地图的标签,当团队查看地图的标签是否与专家的“黄金标准”标签匹配时,它有 93% 的时间这样做。
“在美国,我们也看到了超过90%的准确率,而在印度之前的工作中,我们只看到了75%,因为地面标签有限,”Wang说。“现在,我们可以以一种廉价和自动化的方式创建这些标签。
研究人员正在绘制印度各地的农作物地图,最近通过谷歌街景和其他服务提供了路边图像。
“印度有超过1.5亿小农户,”王说。“印度被农业覆盖,几乎是墙到墙的农场,但农场非常小,从历史上看,绘制印度地图非常困难,因为地面标签非常稀疏。
该团队正在努力在印度生成作物地图,随着全球气温和人口的上升,这些地图可用于为与评估和提高产量有关的政策提供信息。
“有趣的是随着时间的推移创建这些地图,”Wang说。“然后你可以开始看到趋势,我们可以尝试将这些事情与气候和政策的变化联系起来。
新闻旨在传播有益信息,英文版原文来自https://news.mit.edu/2024/mit-researchers-remotely-map-crops-fields-0215