
选举期间的假机器人电话。一个公众人物的声音被挪用到兜售产品。图片被篡改以误导公众。从社交媒体帖子到名人的声音,人工智能生成内容的可信度受到抨击。因此,这里有一个紧迫的问题:我们如何在不抑制创新的情况下消除有害或不良内容?
加州大学圣地亚哥分校雅各布斯工程学院的计算机科学家提出了一种新的解决方案,可以优化深度生成模型的巨大潜力,同时减少产生有偏见或有毒的内容。
在 2024 年 IEEE 安全可信机器学习论文《 来自条件生成模型的数据编辑》中,研究人员引入了一个框架,可以防止文本到图像和语音合成模型产生不良输出。他们的创新方法在本月早些时候在多伦多大学举行的IEEE会议上获得了杰出论文奖。
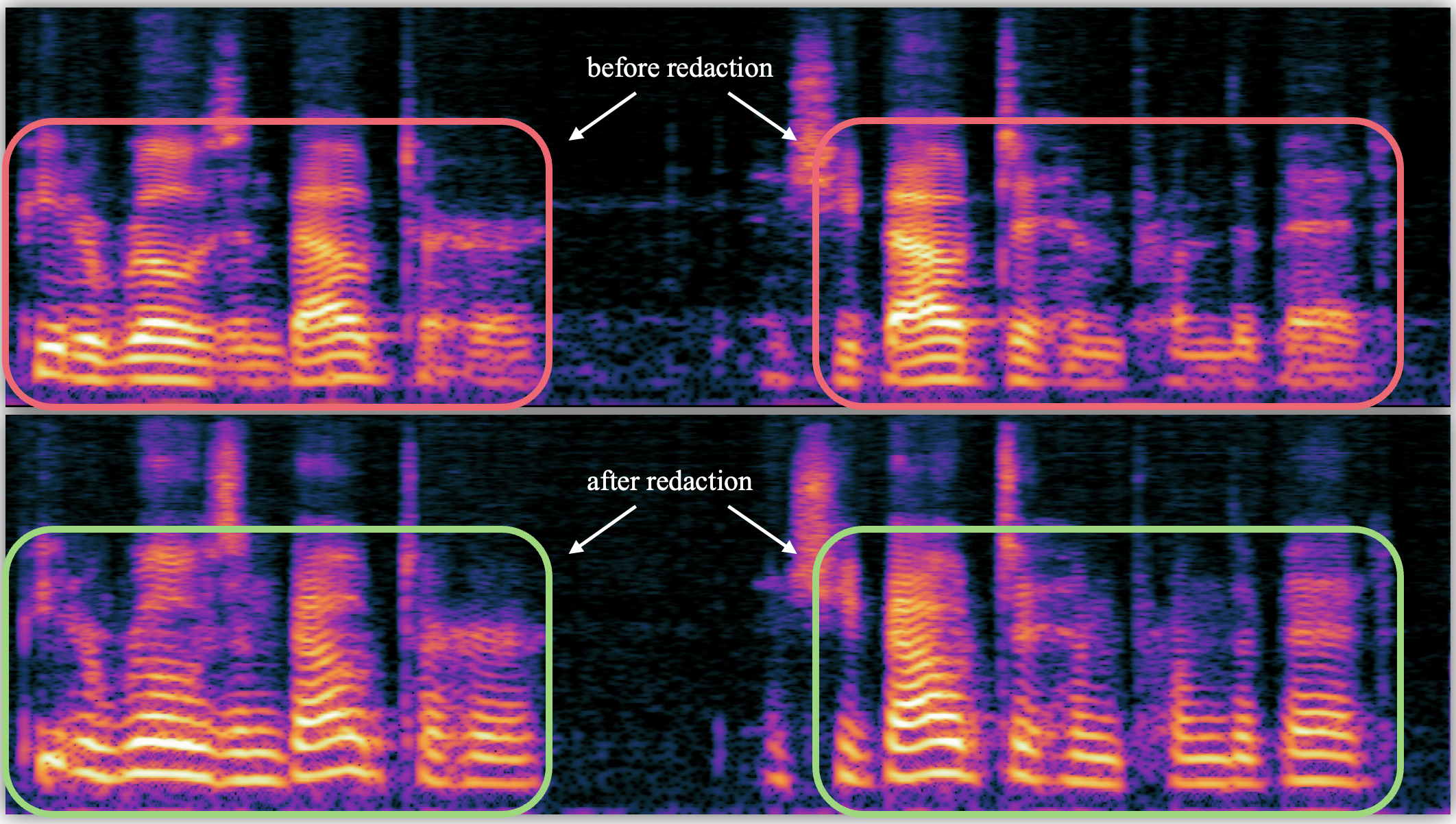

“现代深度生成模型经常产生不良输出,例如冒犯性文本、恶意图像或捏造的言论,并且没有可靠的方法来控制它们。这篇论文是关于如何在技术上防止这种情况发生,“计算机科学与工程系博士毕业生、该论文的主要作者Zhifeng Kong说。
“这项工作的主要贡献是正式确定了如何思考这个问题以及如何正确地构建它以便解决它,”计算机科学教授Kamalika Chaudhuri说。
一种消除有害物质的新方法
传统的缓解方法采用两种方法之一。第一种方法是使用排除所有不需要样本的训练集从头开始重新训练模型;另一种方法是应用分类器,在生成内容后过滤不需要的输出或编辑输出。
对于大多数现代大型模型,这些解决方案具有一定的局限性。除了成本高昂(需要数百万美元从头开始重新训练行业规模模型)之外,这些缓解方法的计算量很大,并且无法控制第三方在获得源代码后是否会实施可用的过滤器或编辑工具。此外,它们甚至可能无法解决问题:有时,即使训练数据中不存在,也会出现不需要的输出,例如带有伪影的图像。
Chaudhuri 和 Kong 的目标是在克服这些障碍的同时减少不受欢迎的内容。他们受到启发,设计了一个正式的统计机器学习框架,该框架有效、通用且计算高效,同时保持了高生成质量。
具体来说,该团队建议对预训练模型的权重进行后编辑,他们称之为数据编辑。他们引入了一系列技术来编辑某些条件或用户输入,这些条件或用户输入将具有很高的统计概率导致不良内容。

之前的数据编辑工作主要集中在 无条件 生成模型上。这些研究考虑了输出空间中的问题,编辑了生成的样本。同样的技术太笨拙了,无法应用于 条件 生成模型,条件生成模型通常学习无限数量的分布。
Chaudhuri 和 Kong 通过在条件空间而不是输出空间中进行编辑来克服这一挑战。对于文本到图像的模型,他们编辑了提示;在文本转语音模型中,他们编辑了语音。简而言之,它们在火花被扇成有毒输出之前就熄灭了火花。
例如,在文本转语音上下文中,他们可以编辑特定人员的声音,例如名人的声音。然后,该模型将生成一个通用的声音来代替名人的声音,这使得将单词放在某人的嘴里变得更加困难。
该团队的方法(只需要加载数据集的一小部分)在计算上保持了数据编辑的轻量级。与基线方法相比,它还提供了更好的编辑质量和鲁棒性,并保留了与预训练模型相似的生成质量。
研究人员指出,这项工作是一项小规模研究,它提供了一种适用于大多数类型的生成模型的方法。
“如果这要扩大规模并应用于更大和更现代的模型,那么最终更广泛的影响将是通往更安全的生成模型的道路,”Chaudhuri说。
这项工作得到了美国国家科学基金会(1804829)和陆军研究办公室MURI奖(W911NF2110317)的支持。
新闻旨在传播有益信息,英文版原文来自https://today.ucsd.edu/story/fighting-ai-fire-with-ml-firepower